CoreLM
Local AI, Perfected
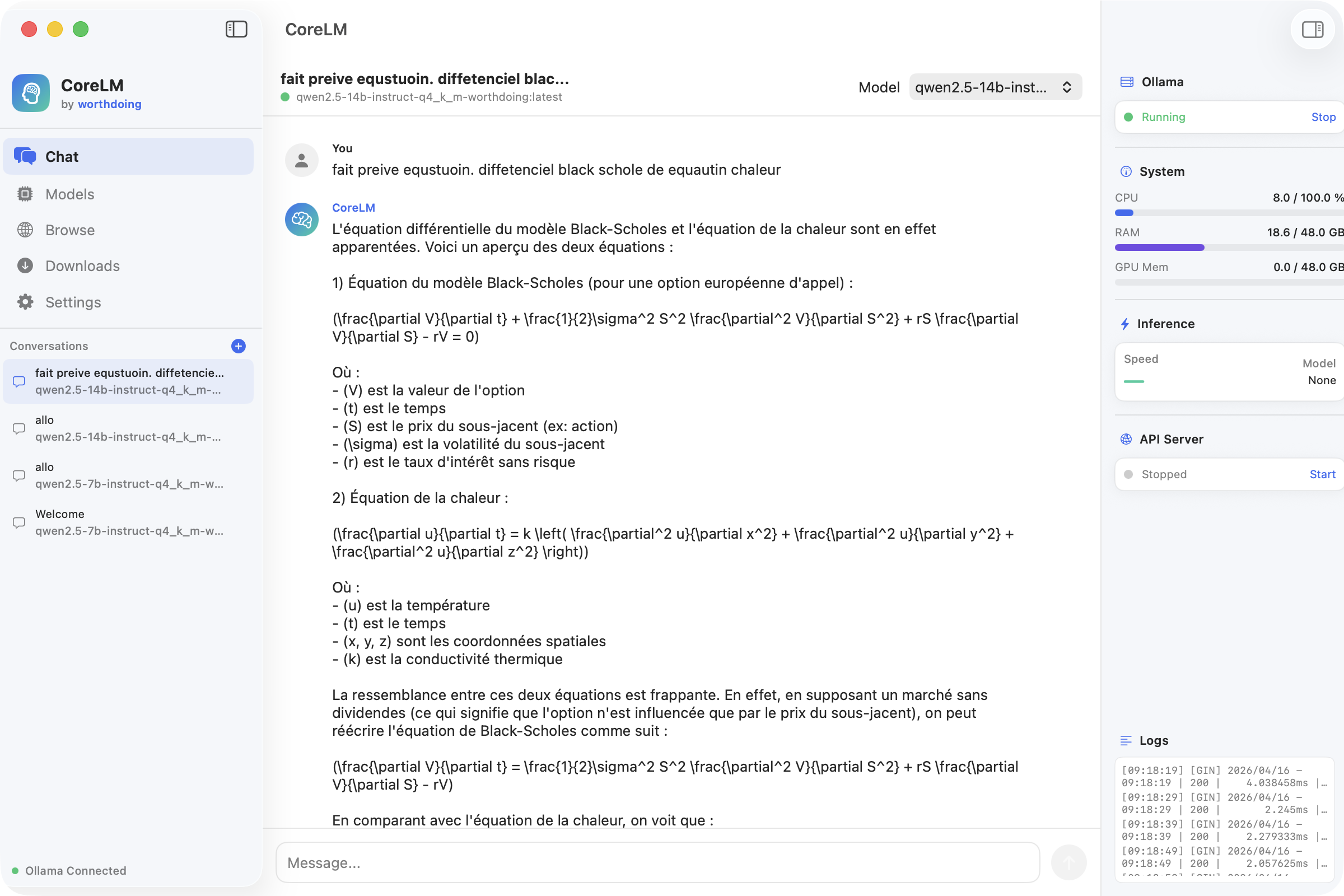
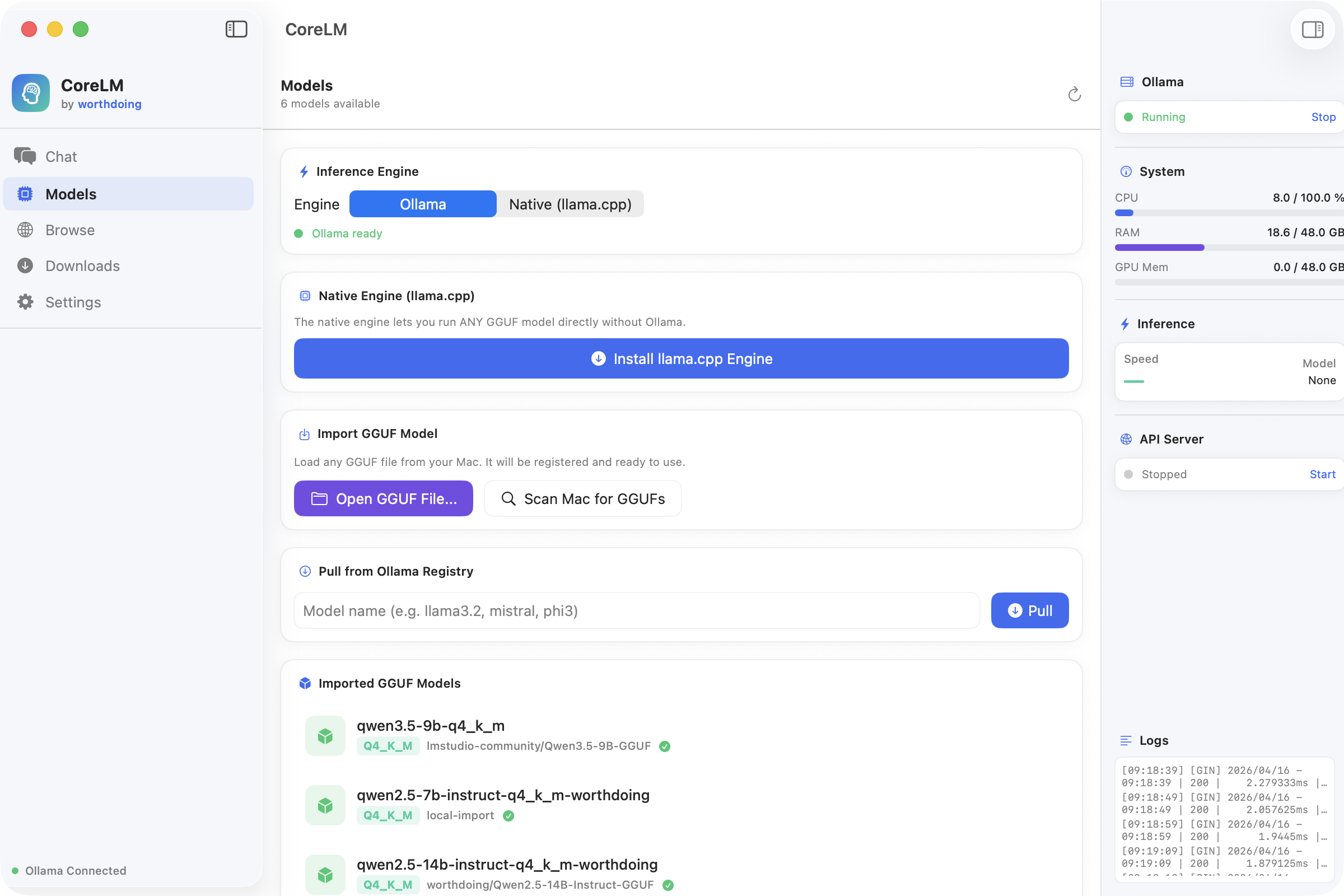
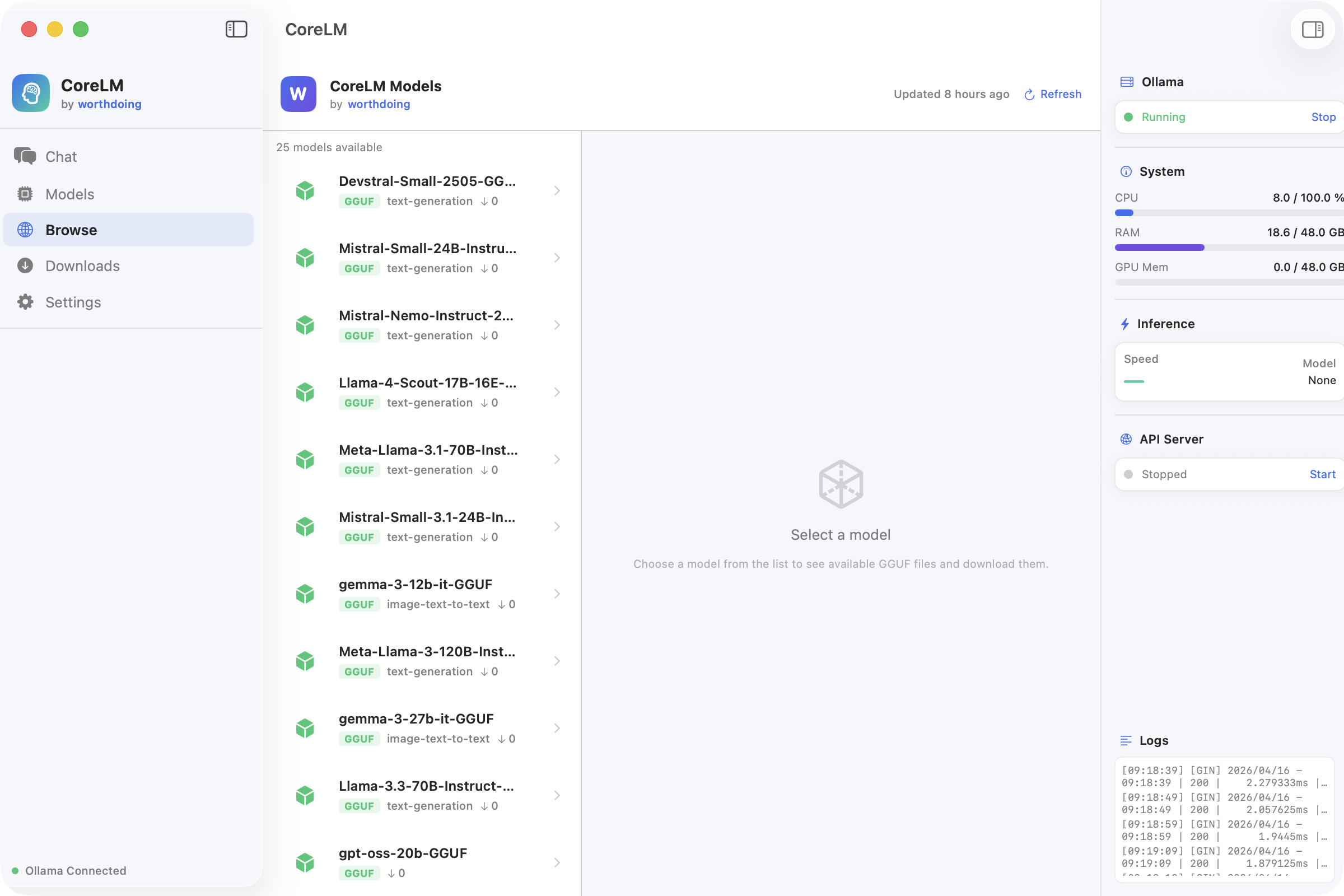
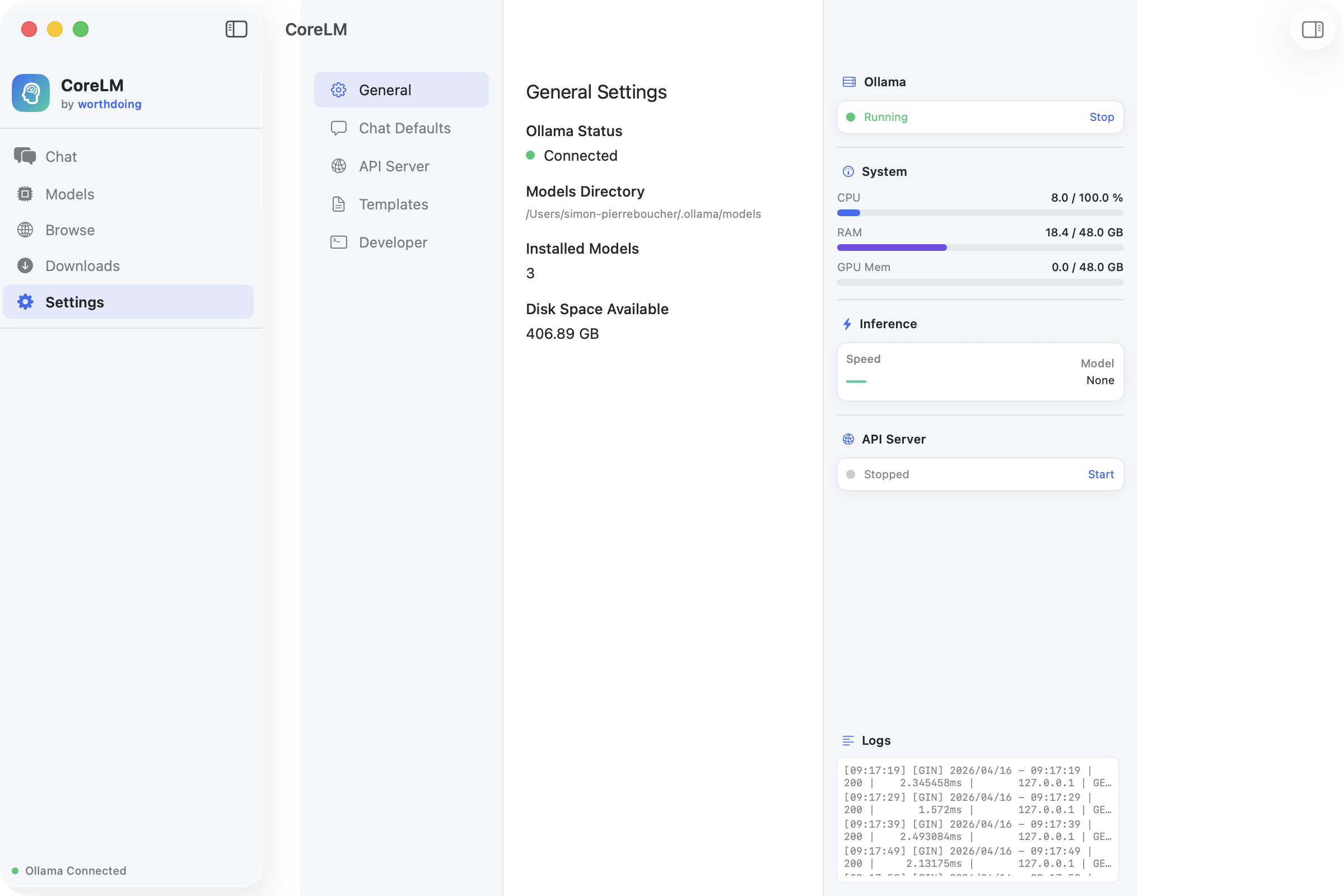
A fully native macOS application for running large language models locally. Dual inference engine architecture (Ollama + llama.cpp), one-click model downloads from Hugging Face, streaming chat with markdown rendering, and real-time system monitoring.